| |
Один процессор — хорошо, шестнадцать — лучше
Были времена, когда использовалась только жёсткая логика. Процессоры, как правило, потребляли большую мощность и требовали наличия больших объёмов памяти. Но ситуация меняется, по крайней мере, в области сетевых и телекоммуникационных приложений. Если даже бегло взглянуть на ряд последних разработок, легко заметить тенденцию к использованию большого числа процессоров в системах, перемалывающих огромные объёмы информации в виде пакетов и фреймов между уровнем канала передачи данных и приложением.
Если ещё два года назад многопроцессорная система была бы нерентабельна, то самые последние разработки предлагают решения много более эффективные, чем один сверхмощный RISC-процессор и целая куча заказных микросхем. Это стало возможным потому, что некоторые компании смогли разместить целых 32 отдельных процессора в одной микросхеме!
Вместо того, чтобы тратить время на наращивание производительно-сти отдельных ядер процессоров, ряд вновь образованных компаний, таких как C-Port и Hyperchip, а также некоторые именитые компании, например, Intel и Sun, решили сконцентрироваться на многопроцессорной обработке как главном способе обеспечения высокой скорости коммутации и маршрутизации пакетов.
Главной движущей силой стало, как это не удивительно, развитие всемирной сети Internet. Но это связано не только с ростом затрат на электропитание всей инфраструктуры телекоммуникационного оборудования. Проблема с сетью Internet состоит в том, что она смещает ориентиры. Производители сетевого оборудования никогда не знают, какие новшества появятся завтра и какое из них станет самым популярным, но они уверены наверняка, что новшество появится обязательно, и надо будет быстро перестроиться и научиться его поддерживать. Если оборудование достаточно гибкое и допускает программную переконфигурацию, производители должны быть способны выполнить запросы рынка быстрее конкурентов, пытающихся разрабатывать специализированные микросхемы (ASIC). Имеется также проблема объёмов партий выпускаемых изделий. Разработка заказных микросхем с высокой степенью интеграции — дело дорогое и рискованное. Если же у производителя есть возможность использовать программное обеспечение для настройки универсального коммутатора в каждом специфическом приложении, то это позволяет сэкономить средства в условиях выпуска крупных партий стандартных изделий.
Наконец, имеется определённый спрос на более интеллектуальные коммутаторы. Поставщики Internet-услуг хотели бы использовать различную скорость передачи данных в зависимости от запрошенного качества обслуживания (QoS). Компания, осуществляющая передачу важной финансовой информации через Internet, должна обслуживаться иначе, чем конечные пользователи, сидящие дома и занимающиеся просто посещением web-сайтов.
Если коммутатор может обнаружить различие между двумя пакетами, отдельные пользователи могут получить приоритет. Процессоры, выполняющие маршрутизацию, должны уметь быстро проанализировать пакеты данных и определить, для каких приложений они предназначены, после чего разместить их в разные очереди.
Имеются два типа процессоров, конкурирующих в данной отрасли. Самой большой группой является C-5 производства компании C-Port, а также IXP производства компании Intel. Оба процессора предназначены для формирования базиса двух конкурирующих стандартов построения сетевых коммутаторов. Компания IBM выбрала C-5 как главный процессор для построения своего оборудования. Компания Intel пробует делать то же самое с IXP, продвигая новую шину как средство связи контроллеров физического уровня и уровня данных, для построения матричных коммутаторов и другого сетевого оборудования. Причём компания настолько увлечена этим, что поощряет поддержку сторонних фирм и уже выделила 200 млн. долларов на развитие компаний, намеренных ориентировать свое программное и аппаратное обеспечение на IXP-платформу.
Максимальное число процессоров, объединённых на сегодняшний момент на одном кристалле С-5, равно 37, причём они делятся на два типа. Одна из разработок, использующая 17 ядер на кристалле, базируется на сокращённой версии MIPS-архитектуры. Это даёт возможность разрабатывать код с помощью инструментального пакета Gnu. Один из этих процессоров используется как системный контроллер, отслеживающий работу остальных RISC-процессоров и координирующий доступ для отладчиков.
Остальные 20 процессоров более специализированы, например, 16 из них используются для побитовой и побайтовой обработки последовательных потоков данных и освобождают RISC-процессоры от операций обработки протоколов нижнего уровня. Они исполняют такие функции, как проверка циклических контрольных кодов (CRC) и битовые манипуляции на адресах пакетов. Работа по обработке данных на верхних уровнях протокола передаётся RISC-процессорам.
Оставшиеся несколько процессоров действуют как совместно используемые сопроцессоры для RISC-ядер. Каждый из них оптимизирован для выполнения какой-либо определённой операции, например, обработки поисковых таблиц для трансляции IP-адреса, управления очередью, связи коммутируемой части оборудования с процессорами классификации трафика.
Для связи между процессорами используются три типа шин. Для передачи основного потока пакетов данных используется широкополосная шина, другая используется для обеспечения межпроцессорных связей, а третья — для работы с адресными поисковыми таблицами. Большая часть памяти, необходимой устройству C-5 для буферизации полезной информации, хранения адресной информации и данных об очерёдности пакетов, находится во внешнем запоминающемся устройстве. Встроенная память используется для оперативного хранения небольших объёмов данных и кода программы. Построенный на базе хост-процессора StrongARM, процессор IXP1200 был создан командой разработчиков, приобретённой компанией Intel у фирмы Digital. Помимо ядра процессора StrongARM, устройство имеет 6 32-разрядных микроядер. Хотя их всего 6, каждое может одновременно управлять четырьмя потоками одновременно (то есть всего 24), — таким образом компания сделала попытку максимизировать производительность системы. В достаточно простых трёхуровневых маршрутизаторах такая система из процессора StrongARM и шести микроядер пересылает до 2,5 млн. пакетов в секунду.
Каждое микроядро имеет 32-разрядное арифметико-логическое устройство, способное обрабатывать подслова и элементы битового уровня. Как и в случае с процессором C-5, микроядра выполняют код, который хранится в локальном запоминающем устройстве и может содержать до 1000 команд. Код управления микроядрами для трёхуровневого маршрутизатора занимает около 60% всей доступной для программы памяти. В рабочем режиме потоки, обрабатываемые в каждом микроядре, как правило, блокируются, когда происходит запрос данных от одного из главных устройств хранения: SRAM для адресов или SRAM для пакетов полезной информации. Этот запрос поступает на специальный конечный автомат микроядра, который блокирует поток, позволяя запустить обработку другого.
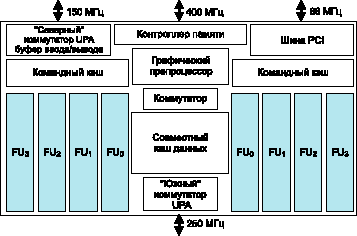
Рис. 1. Блок-схема процессора MAJC5200 компании SUN
Когда данные поступают в заданный регистр, конечный автомат открывает блокирующий поток семафор, данные перемещаются в регистр FIFO, и их обработка будет выполнена на следующем этапе.
Многопотоковый подход лежит в основе другого однокристального мультипроцессора MAJC производства компании Sun. Компания нацелена не на решение задач сетевой коммутации, а на обработку информации в шлюзах и порталах, и главную проблему видит в том, что разработчики пытаются использовать процессоры с обычными архитектурами. Вместо того, чтобы делить микросхему на десятки процессоров, компания Sun использует решение, представляющее собой нечто среднее между архитектурой процессора с командными словами очень большой длины (VLIW), например, TriMedia компании Philips, и с классической RISC-архитектурой. Каждый процессор представляет собой набор кристаллов, связанных между собой блоком регистров. В этом случае, микросхема может иметь два, как в самом первом изделии, или большее количество таких суперпроцессоров.
Процессор MAJC исполняет программу, записанную во внешнюю память через кэширующее устройство, а значит, здесь должна быть применена многопотоковая обработка, тем более, что тактовая частота равна 500 МГц. Если один сеанс доступа к DRAM занимает 75 циклов, то коэффициент “непопаданий” в кэш на уровне 5% приведёт к снижению полной производительности процессора на 20%. Как и в случае с изделием компании Intel, способность быстрого переключения между потоками способствует конвейерной обработке информации. Архитектура Sun была специально разработана для обработки информации о состоянии нескольких потоков за счёт разделения блока регистров на несколько виртуальных групп. При “промахе” кэша процессор переключается на следующий поток, подключает соответствующую группу регистров и продолжает работу, пока данные ожидают своей очереди в кэше. По мнению специалистов компании, такая система, поддерживающая четыре независимых потока данных, позволит довести использование процессора почти до 100%.
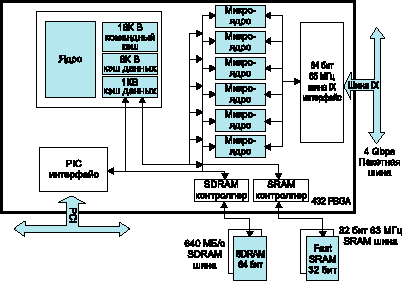
Рис. 2. Блок-схема процессора IXP1200 фирмы INTEL
Устройства MAJC поддерживают как классический набор команд, так и систему SIMD (один поток команд, несколько потоков данных), используемую процессором UltraSparc компании Sun. В процессоре MAJC их длина будет ограничена 8 разрядами, вместо привычных 16 и 32. Архитектура MAJC допускает выполнение Java-кода, но информационные секции, написанные для определённого прикладного интерфейса (API), будут компилироваться для каждой версии MAJC по-разному. Это позволит коду использовать преимущества наличия нескольких встроенных ускоряющих модулей. Таким образом, главным направлением в развитии микропроцессоров для телекоммуникационного оборудования является наращивание числа процессорных ядер и объёма программного обеспечения. Другой вопрос, который стоит перед разработчиками таких систем, — как правильно писать программы для таких процессоров и как их отлаживать? Но об этом — в следующих публикациях.
CIE, октябрь 1999
Перевод Ю. Потапова
|